


7th issue! If you missed them, you can read the previous issues of the Machine Learning Monthly newsletter here.
Hey everyone, Daniel here, I'm 50% of the instructors behind the Complete Machine Learning and Data Science: Zero to Mastery course (there are now 27,000 students taking this course 🤯. Thank you!). I also write regularly about machine learning and on my own blog as well as make videos on the topic on YouTube.
Welcome to the seventh edition of Machine Learning Monthly. A 500ish (+/-1000ish, usually +) word post detailing some of the most interesting things on machine learning I've found in the last month.
Since there's a lot going on, the utmost care has been taken to keep things to the point.
What you missed in July as a Machine Learning Engineer…
What I made to help you this month 👇
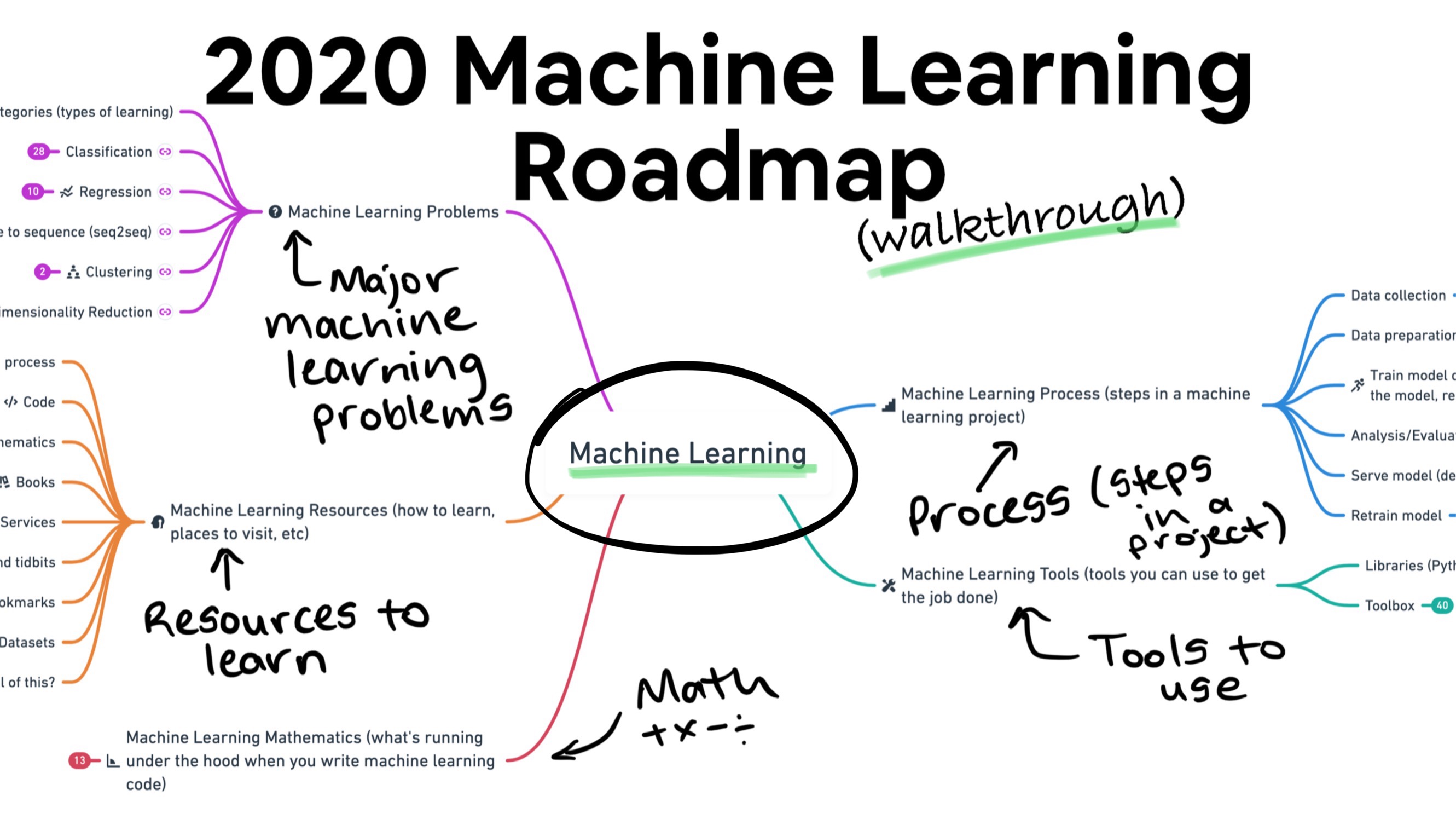
- The 2020 Machine Learning Roadmap (video walkthrough) is here! If you've ever wanted a feature-length film walkthrough of many of the most fundamental concepts in machine learning, the full 2020 Machine Learning Roadmap video walkthrough will help you. You can also jump straight to the interactive roadmap. Better yet, use them both!
- An interview with Ken Jee (Head of Data Science at Scout Analytics and data science YouTuber). Ken interviewed me about how I got started in machine learning and data science, how I landed a job and more. I also interviewed him about what he looks for in a junior data scientist (when he's hiring) and some of the lessons he's learned going to university for computer science versus teaching himself online.
The best from the internet
We're gonna go for a different style this month. Since a couple of things are on similar topics, I thought I'd group them together.
All about GPT3 🤖
You might've seen GPT3 all throughout the machine learning world the past month or so. And if you're like me, you've even signed up to OpenAI's API beta to test it out.
However, if you missed it, GPT3 is of the latest advancements in language modelling.
You can think of a language model as a model which tries to understand how words should be placed together (say, in a sentence or paragraph) by looking at large amounts of text corpora (for example, the entirety of Wikipedia).
Why are language models important?
Language is how we communicate. It's what enables me to take a thought from my head, put it into these lines and then have the thought somewhat reconstructed in your head.
Older language models used to consist of many hand crafted rules. Such as where a certain word should or shouldn't appear in a sentence but as you could imagine, building these systems takes an incredible amount of time and expertise.
More recent advances (such as GPT3) have taken an unsupervised approach, such as, having a large (175 billion parameter) model look at basically the entirety of all the text on the internet and figure out the underlying rules of language.
For example, it could be as simple as knowing that the word dog is more likely to appear in the sentence, "I love my pet ___" than the word car.
Or as complicated as generating a three sentence summary of a 3,000-word article.
Why is GPT3 especially important?
Put it this way, in the paper announcing GPT3, the authors state that text generated by GPT3 (i.e. you give GPT3 a prompt such as "write an article about climate change") was almost indistinguishable from text written by humans. More specifically, for the largest GPT3 model, a group of people were 52% accurate at guessing whether a 500 word article was written by GPT3 or a human (pure guessing would result in ~50% accuracy).
If you want a first hand example of this kind of text generating power, read the article OpenAI's GPT-3 may be the biggest thing since bitcoin.
GPT3 also flourishes on many other natural language processing benchmarks, setting new records as state-of-the-art across a range of categories, even though it was never explicitly trained to do any of them. I'll leave these to be discussed more in the complete Cornell paper, titled "Language Models are Few-Shot Learners".
In the meantime, if you're interested in learning more about GPT3, you'll want to check out the following resources:
- GPT3 awesome — a collection of some of the amazing (and sometimes scary) use cases of GPT3.
- GPT3 paper explained video — the GPT3 paper is a hefty read (~40 pages), this walkthrough video by Yannic Kilcher does a great job of explaining many of the most important concepts.
- GPT2 illustrated — Jay Alammar's posts are world-class when it comes to explaining technical concepts in a visual way and his post on GPT2 (the predecessor to GPT3... GPT3 is actually a scaled up version of GPT2) does a great job going through what's going on behind the scenes.
- Update: he's currently working on a similar post for GPT3, as of writing, it's a live work in progress.
- GPT2 annotated (with code) — whilst Jay's post gives a great high-level overview of GPT2, Aman's annotated GPT2 post goes into replicating the GPT2 architecture with code examples and explanations throughout. A phenomenal example of sharing technical work.
📃 Research — Screw labels, automate & self-supervise
Two trends I'm noticing of late:
- A move towards more and more automated machine learning (AutoML).
- A move towards more self-supervised (also referred to as unsupervised) models.
AutoML seeks to create machine learning architectures with as little input from a human as possible.
Self-supervised models are models which use techniques to learn about the data they're working on with a fraction (or none) of the labels used in supervised learning techniques.
GPT3 (mentioned above) uses absolutely no labels yet performs incredibly well on many language tasks.
The interesting part here will be the crossover of the two. When you think about how a baby learns, they don't use millions of labelled examples, you can show a toddler a photo of a single bird and she'll be able to identify another photo of a bird.
Now, imagine having a dataset of millions of examples of self-driving car scenarios. Instead of having humans annotate every single example, you could label a random sample of 1-10% of scenarios. Once you've done this then have AutoML design a self-supervised system to figure out what of those 1-10% scenarios relate most to the other scenarios and use similar learned actions for each.
Going back to the example before, a human doesn't need to see 100 examples of a skateboarder crossing the street to know they usually move faster than a pedestrian, one (or none, if they've seen skateboarders out side of a driving situation) is enough.
Here are some of the latest breakthroughs in AutoML and self-supervised learning:
- Evolving code that learns (AutoML-Zero) — traditional AutoML takes the building blocks of neural networks (convolutions, dropout) and tries to find the best way to combine them. How about if you started completely from scratch? Say with just basic mathematical operations such as addition, multiplication, etc. Well that's what AutoML-Zero does. And using evolutionary algorithms, it rediscovers fundamental machine learning paradigms such as backpropagation and linear regression.
- Self-supervised learning on images — Facebook's new framework SwAV (Swapping Assignments between Views) provides a simple framework for the unsupervised training of Convolution Neural Networks (CNNs). And it can perform almost as well as supervised models using a fraction of the labels.
- State of the art text summarisation with PEGASUS — summarizing a passage of text is a challenging task. It requires understanding the text itself and then producing a compressed version of it. Google's new PEGASUS (Pre-training with Extracted Gap-sentences for Abstractive Summarization) produces state of the art results on several text summarization benchmarks using guess what, self-supervised learning.
- Bonus: Train your neural nets more efficiently (and get better performance) — it's no secret training machine learning models takes a lot of compute power. But a new paper by Google, Go Wide, Then Narrow: Efficient Training of Deep Thin Networks finds a way to train smaller neural networks to perform just as well as larger neural networks. This is huge for putting machine learning models into production (smaller models = less computation = cost savings).
Learn — Don't let your machine learning models die in a Jupyter Notebook
Okay, we've talked enough, let's go for a quick fire round.
- The full-stack deep learning is open source — if you've ever wanted to ship an application which uses deep learning, do this course.
- Deploy machine learning models with Django — speaking of deploying a machine learning model, this extensive guide will show you how to do it with Django (a Python-based web framework).
- DeepMind + UCL (London's Global University) deep learning series — a YouTube playlist going through the fundamentals of deep learning from two of the best in the business.
Watch/Read — The future won't be supervised
We've been speaking a lot about self-supervised learning (and you can expect more of this in the future).
So what exactly is it?
These resources will help build the motivation and intuition behind it.
- Yann LeCun (head of AI research at Facebook) talks the future of AI with TED — one of the OG's of neural networks speaks for an hour with the host of TED about self-supervised learning, how Facebook uses AI and what he see's as the future of AI.
- The Future of Computer Vision is Self-Supervised Learning — a more technical overview of self-supervised learning by Yann LeCun flavoured in computer vision style.
- Self-supervised learning and computer vision by Jeremy Howard — possibly the internet's favourite AI educator explains how self-supervised learning in computer vision works in this comprehensive blog post.
- Semi-supervised learning overview by Amit Chaudary — Amit's machine learning posts are quickly becoming some of my favourites on the internet and this one is no different. A great overview of some of the most recent techniques for semi/self-supervised learning. If you haven't checked out Amit's blog yet, you should.
See you next month!
And that's it for July.
As always, let me know if there's anything you think should be included in a future post. Liked something here? Send us a tweet.
In the meantime, keep learning, keep creating.
See you next month,
Daniel www.mrdbourke.com | YouTube
By the way, I'm a full time instructor with Zero To Mastery Academy teaching people Machine Learning in the most efficient way possible. You can see a couple of our courses below or see all Zero To Mastery courses by visiting the courses page.











