


50th issue! If you missed them, you can read the previous issues of my monthly A.I. & Machine Learning newsletter here.
Hey there, Daniel here.
I’m an A.I. & Machine Learning Engineer who also teaches the following beginner-friendly machine learning courses:
- Complete A.I. Machine Learning and Data Science Bootcamp: Zero to Mastery
- TensorFlow for Deep Learning: Zero to Mastery
- PyTorch for Deep Learning: Zero to Mastery
- [NEW] Project: Build a custom text classifier and demo with Hugging Face Transformers
- [NEW] Machine Learning with Hugging Face Bootcamp
I also write regularly about A.I. and machine learning on my own blog as well as make videos on the topic on YouTube.
Since there's a lot going on, the utmost care has been taken to keep things to the point.
Enough about me! You're here for this month's A.I. & Machine Learning Monthly Newsletter.
Typically a 500ish (+/-1,000ish, usually +) word post detailing some of the most interesting things on machine learning I've found in the last month.
Here's what you might have missed in February 2024 as an A.I. & Machine Learning Engineer... let's get you caught up!
My Work 👇
My brother and I have been working on an AI-powered food education startup called Nutrify (take a photo of food and learn about it 📸 → 🍍). And the launch video/launch blog post just went live!
If you’ve got an iPhone with iOS 16+, download Nutrify for free and try it out 😀.
From the Internet 👇
Why does my model produce different results? Sampling strategies might be to blame. Guide by Chip Huyen
Machine learning models are probabilistic in nature. This includes LLMs.
This is why it can be confusing that with the same input, the same model has different outputs.
There are techniques to adjust this such as the temperature variable (higher for more creative and lower for more deterministic).
In this guide on sampling methods, Chip explains many of the different sampling methods for text generation models such as top-k sampling (get the top-k results by index and filter those), top-p sampling (get the top-p results up to a certain probability), structuring outputs (get an LLM to output valid JSON or something similar) and more.
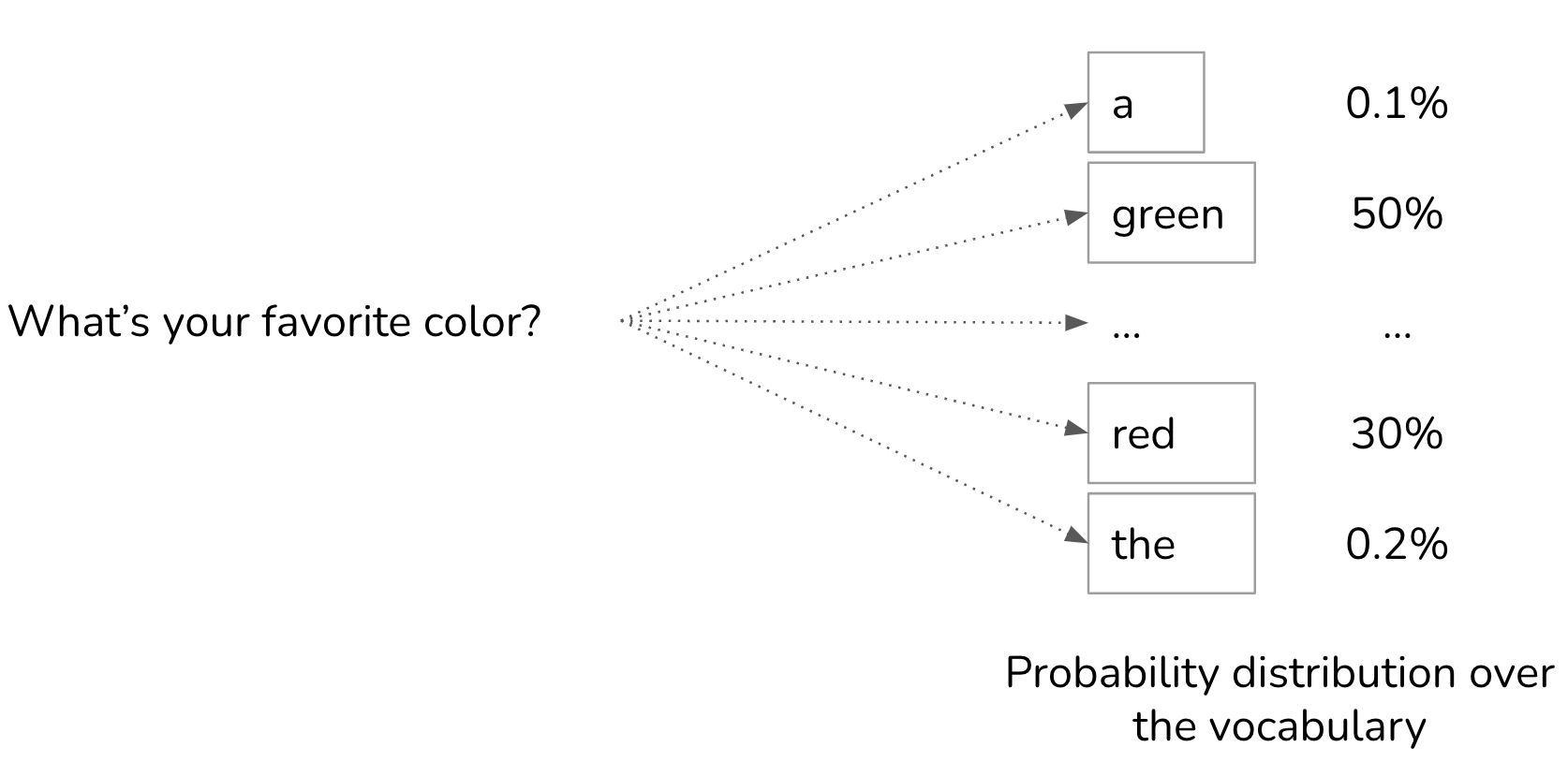
When you query a language model, its response is based on a probability distribution of the vocabulary it was trained with. Essentially it asks the question, “based on the previous sequence of words, which next word is the most likely?”. Source: Chip Huyen blog.
AI-powered Checkouts in India’s Largest Grocer
Excellent write up of an AI-powered checkout system at BigBasket, India’s largest online food and grocery store.
Shows how you can go from data collection (300 images per 12,000 SKUs = ~4,000,000 images) to deploying a real-world AI-powered self-checkout system which performs 30K+ detections per day (possibly much more now since the numbers are from a few months ago).
In a separate blog post by the BigBasket team, they detailed some of the problems you’ll often run into when deploying an AI system to the world and how to deal with them (hint: when one AI model isn’t enough, try simplifying the problem and combining it with another).
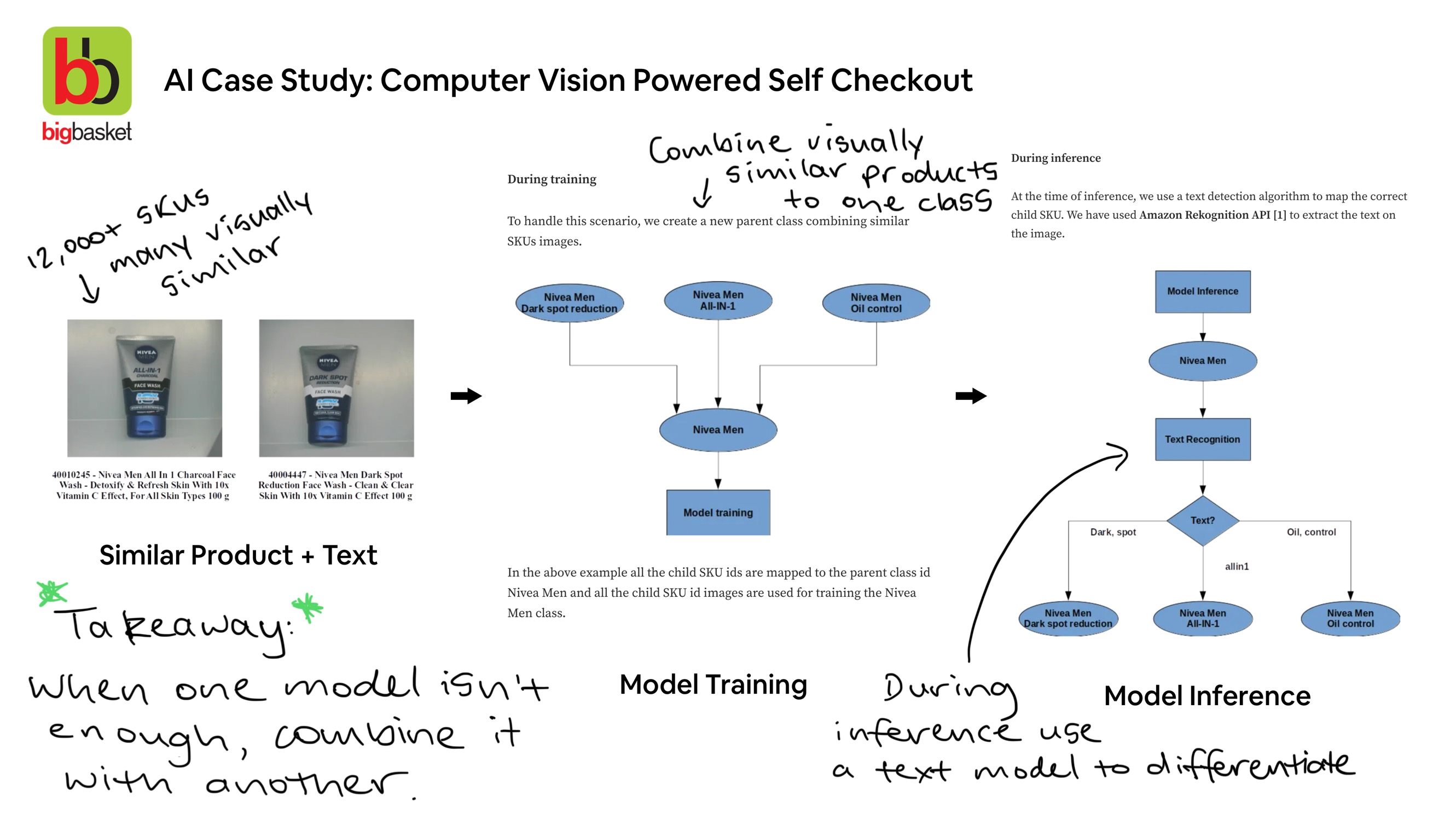
When dealing with 12,000+ different products, many of them can be visually similar. So what do you do when a vision model alone isn’t enough? You simplify the problem and bring in a text-detection model as well. Source: BigBasket tech blog, annotations by the author.
Does ChatGPT work better if you give it a tip? by Max Woolf
There are many prompt engineering techniques that have been figured out.
But this is one of the funniest I’ve heard.
And it kind of makes sense.
If LLMs are designed to be helpful assistants to humans, and they’re trained on data from humans, do they have human incentives?
As in, will they do better work when offered a tip?
Or will they perform better in order to avoid suffering a loss (e.g. “Complete this sentence correctly or you will DIE...”)?
Like all good data scientists, Max Woolf does some experimenting to find out.
Pushing the limits of ChatGPT’s structured data capabilities, a comprehensive guide by Max Woolf
One of the best use cases I’ve found with LLMs is their ability to transform unstructured data into structured data (e.g. raw doctor’s notes into a valid JSON) and vice versa (e.g. a table of information into an easy to digest paragraph of text).
And Max Woolf has a sensational walkthrough of different use cases and methods for getting the GPT API to output structured data with the help of Pydantic (a Python data validation library).
One of my favourite techniques in the blog post is the Two-Pass Generation.
Get the LLM to output one version of an output on the first pass (potentially incorrect) and then get it to refine that output on the second pass.

LLMs are quite good at generating an adequate response on the first pass. But the two-pass generation technique allows an LLM to use its first response as inspiration and improve upon it. Source: Max Woolf blog.
Use an LLM to label data for you, train a smaller specific model and save $$$ (a guide)
Moritz Laurer just published a guide to saving costs, CO2 emissions and compute by using LLMs to help create synthetic data and then training specific and smaller models on the Hugging Face blog.
Specifically, use Mixtral (an open-source LLM that performs on par with GPT 3.5) to label a dataset of financial data for sentiment analysis/classification and then use that labelled data to train a RoBERTa model (~0.13B) which performs on par with GPT-4 and is much faster and cheaper to run.

Table of pros and cons for using an LLM API versus training your own model on custom data or on synthetic data. Source: Hugging Face blog.
NVIDIA launches a chat application you can run entirely on your own PC
Chat with RTX by NVIDIA provides a chat interface for chatting with your own data, running on your own local GPU.
It offers the ability to upload a document or folder path or even YouTube video link (for the transcript), then it indexes the text and uses RAG (Retrieval Augmented Generation) to answer questions of the target file.
The best part?
It all happens locally on your 30 or 40 series RTX GPU (or NVIDIA Ampere or Ada generation GPUs).
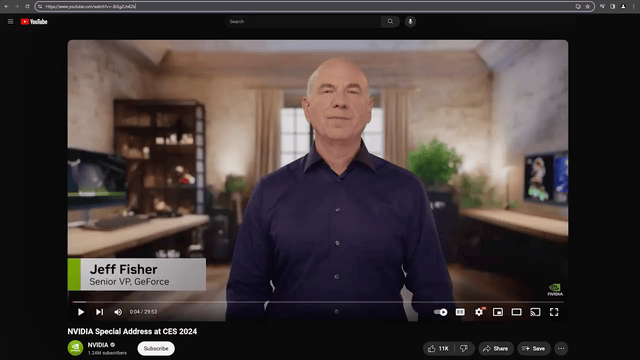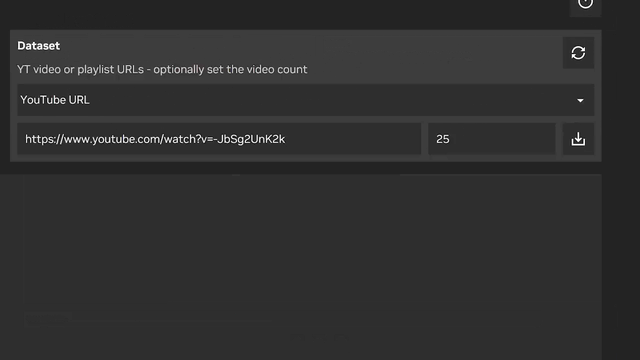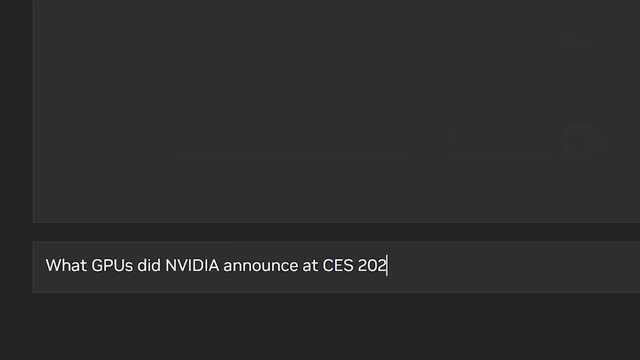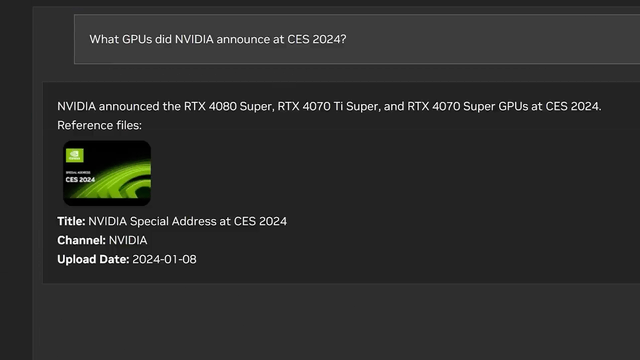
Use NVIDIA’s Chat with RTX app to chat with YouTube videos, files and folders on your local PC. Source: NVIDIA YouTube.
Grounding DINO + Label Studio for open-source image annotation with text prompts
Label Studio is one of the best open-source data labelling tools on the market.
And Grounding DINO is one of the best zero-shot object detection models available.
In their recent guide, the Label Studio team share how you can use Grounding DINO to label images with text-based object detection.
For example, type in “possum” and have Grounding DINO predict a bounding box for where a possum is in an image.
Example of labelling an image in Label Studio with Grounding DINO using the text prompt “possum”. Source: Label Studio blog.
A workflow could be to use Grounding DINO to label images at scale and then review those labels and adjust if necessary in Label Studio.
Bonus: Check out Label Studio’s 5 tips and tricks guide for using their API and SDK.
Research Papers 👇
Prompt Design and Engineering: Introduction and Advanced Methods
Prompt engineering is the art and science of getting an LLM to do what you want. And there are many different techniques. You can ask directly (simple prompting), you can get the model to think about what it should do (chain of thought prompting), and you can get the model to produce multiple outputs for the same question and average the results (self-consistency).
This paper by Xavier Amatriain takes a look at many of the common and effective forms of prompt engineering and design, compares and explains them as well as provides insight into newer techniques such as Automatic Prompt Engineering (APE). An excellent “start here” for anyone looking to learn more about prompt design.
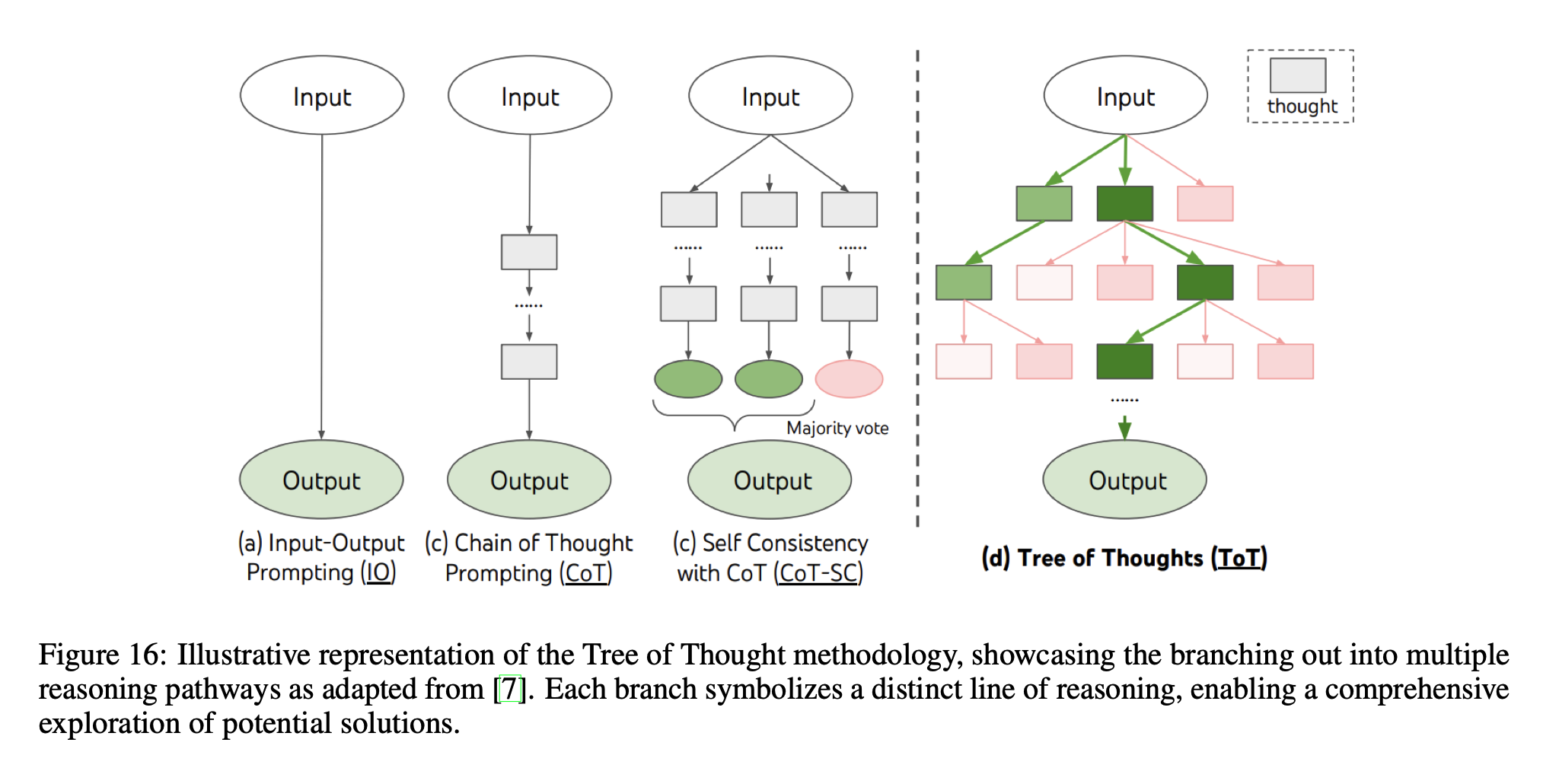
Comparisons of different prompting methods for LLMs. Source: A Primer on Prompt Design paper.
V-JEPA, Video Joint Embedding Predictive Architecture for Self-Supervised World Models
Learn a representation of the world (a world model) by masking out different portions of a video in both space and time and then trying to predict those masked portions based on the unmasked portions.
Kind of like how you would play peekaboo with a child.
They learn about the world by passively observing what moves and what doesn’t. And then when it comes time to specialise on a certain task, much of the required knowledge is built up within their world model. So adapting to something specific doesn’t require thousands of examples, only a few.
See the code on GitHub and read the paper here.
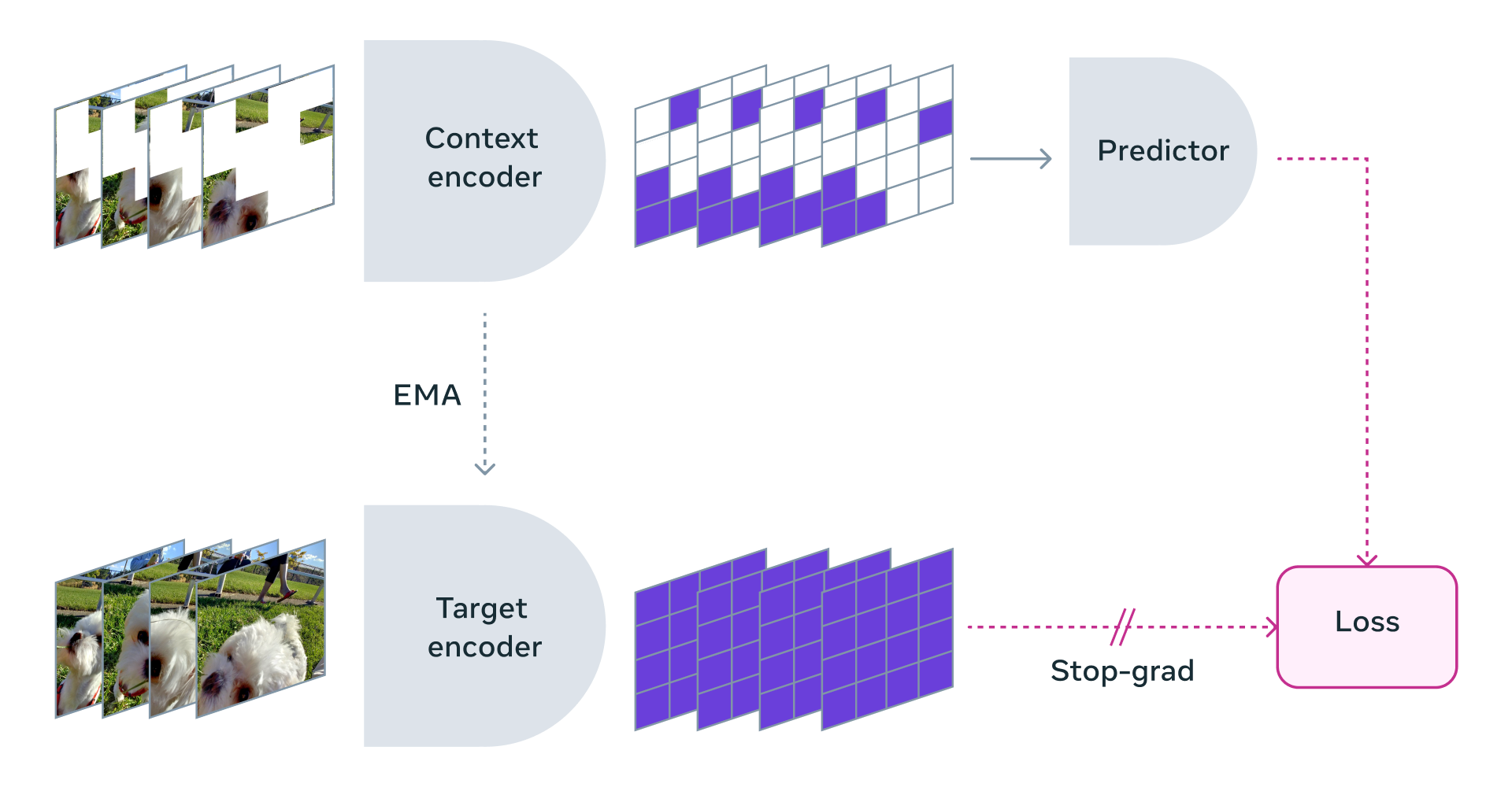
V-JEPA learns a representation of the world by masking out frames in video samples and then trying to predict what should be in those frames. Doing so on video data gives it a representation across both time and space dimensions. Source: Meta AI blog.
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
Which is better? RAG (Retrieval Augmented Generation) or Fine-tuning?
In this study, authors compared the results of three open-source LLMs (Llama2 7B, Mistral 7B and Orca 7B) and their performance on a set of multi-choice questions in various knowledge-improving scenarios.
For their multi-choice questions on topics such as anatomy, astronomy, biology, chemistry and prehistory, they found that RAG almost always outperformed fine-tuning.
And RAG alone often outperformed a fine-tuned base model with RAG.
Of course, results may vary when tried on your own datasets but it’s good to have some research showing the effectiveness of RAG, which is in my opinion, the far simpler approach.
Another one of my favourite takeaways was how the authors created their multi-choice question sets. They used GPT-4 to create a series of questions and answers where only one answer was correct based on a specific piece of text. They then manually went through each of these and verified they were of high quality resulting in a dataset of 910 new questions.

One way to bootstrap an experiment is to use GPT-4 or another high quality LLM to produce synthetic samples and then use those later in combination with real data. Source: Fine-tuning or RAG paper.
Can large language models improve themselves?
Two research papers:
- One from Google: Can large language models identify and correct their mistakes?
- One from Meta: Self-Rewarding Language Models get Llama 2 70B to outperform Claude 2, Gemini Pro and GPT-4 0613) show that the answer is likely: yes.
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Shows how upscaling a data engine with 62,000,000 unlabeled images can lead to incredible results. In this case, making a model that can provide depth maps for any image.
Code on GitHub, demo on Hugging Face.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
This paper introduces Direct Preference Optization (DPO) a technique for improving language models based on a reward model for human preferences (Reinforcement Learning from Human Feedback or RLHF). Authors show that DPO is more efficient than another popular RLHF method PPO (Proximal Policy Optimization).
Salesforce also shows you can use DPO to improve image generation models in line with human preferences. The results of the base model improved with DPO look much more detailed and aesthetic to look at.
YOLO-World: Real-Time Open-Vocabulary Object Detection
Train a detection model on an open-vocabulary of words and add in a language-adapter layer so that it can adapt to previously unseen vocabularies.
For example, predicting “croissant” when the model hasn’t necessarily seen labelled objects of croissant. My favourite part of the paper was the dataset construction. Use a large-scale model to pre-label a bunch of images and use other models to filter those labels and see whether they should stay or not.
See a collection of tricks on the Roboflow blog. Try a demo on Hugging Face.

YOLO-World is capable of detecting objects in images based on text-prompts in real-time. Source: Slaksip92 on X.
Open Source 👇
- Cohere releases Aya, the most multilingual language model there is.
- Google releases two state of the art open-source LLMs (2B and 7B in size) called Gemma. See a guide on Hugging Face.
- Surya is an open-source text detection and OCR engine that works on 90+ languages and outperforms Tesseract.
Cool Five ✋
- Apply pandas in parallel (much faster!) with 1 line of code.
- OpenAI demos Sora, a new text-to-video generation model.
- Function calling with LLMs (video guide) by Trelis Research.
- Exciting trends in machine learning (video talk) by Jeff Dean, Google AI lead.
- RAG from scratch tutorial series from LangChain YouTube channel.
See you next month!
Another massive month for the AI & ML world in February!
As always, let me know if there's anything you think should be included in a future post.
In the meantime, keep learning, keep creating, keep dancing.
See you next month,
Daniel
By the way, I'm also an instructor with Zero To Mastery Academy teaching people Machine Learning & AI in the most efficient way possible. You can see a few of our courses below or check out all Zero To Mastery courses.

















