


56th issue! If you missed them, you can read the previous issues of my monthly A.I. & Machine Learning newsletter here.
Hey there, Daniel here.
I’m an A.I. & Machine Learning Engineer who also teaches the following beginner-friendly machine learning courses:
- Complete A.I. Machine Learning and Data Science Bootcamp: Zero to Mastery
- TensorFlow for Deep Learning: Zero to Mastery
- PyTorch for Deep Learning: Zero to Mastery
- [NEW] Project: Build a custom text classifier and demo with Hugging Face Transformers
- [NEW] Machine Learning with Hugging Face Bootcamp
I also write regularly about A.I. and machine learning on my own blog as well as make videos on the topic on YouTube.
Since there's a lot going on, the utmost care has been taken to keep things to the point.
Enough about me! You're here for this month's A.I. & Machine Learning Monthly Newsletter.
Typically a 500ish (+/-1,000ish, usually +) word post detailing some of the most interesting things on machine learning I've found in the last month.
Here's what you might have missed in August 2024 as an A.I. & Machine Learning Engineer... let's get you caught up!
My Work 👇
A new blog called learnml.io — I’ve long had my own personal website (mrdbourke.com) where I’ve published machine learning-related articles in the past. But I decided to create a more ML-focused blog/resource where I can write about anything ML.
The website is bare for now.
But I’ll be creating blog posts, resources and tutorials about tidbits I learn in the ML world.
The first post is live and it’s called The importance of a test set.
Inside, I talk about how making a good test set is one the most important things for any custom ML project (if you can’t test your model well, how can you ship it?).

Comparison of internet data versus real-life data. Internet data is good to get started on many ML problems but to make it work in the real world, you’re going to need real world samples. Image is from a talk I gave on MLOps lessons learned building Nutrify.
From the Internet 🕸
1. Vision Transformer (ViT) vs. Convolutional Neural Network (CNN) speed test by Lucas Beyer
Lucas Beyer is one of my favourite ML researchers. If you’re not following him on X/Twitter, you should.
He’s also one of the co-creators of the ViT architecture.
In On the speed of ViTs and CNNs, Lucas examines how ViTs and CNNs compare on samples per second at various given batch sizes.
His findings show that ViTs can perform as fast or sometimes faster than CNNs at various batch sizes and image resolutions.

ViT architecture versus other kinds of CNN-like architectures (ConvNeXt and NFNet). Source: Lucas Beyer blog.
One of my other favourite takeaways was that on the different image sizes:
My conservative claim is that you can always stretch to a square, and for:
- natural images, meaning most photos, 224px² is enough;
- text in photos, phone screens, diagrams and charts, 448px² is enough;
- desktop screens and single-page documents, 896px² is enough.
This is important because depending on the problem you’re working on, a different image resolution may impact your results.
And using a higher image size often results in more compute required/longer training times.
If you’re training computer vision models, I’d highly recommend reading the blog post, it’s well worth it.
2. How Pinterest built a custom text-to-image foundation model
These are my favourite kind of stories.
A company or startup has a large data resource (or chooses to specialize in a certain thing) and then takes existing research and applies it to make their product better.
Pinterest is a visual platform which among many things helps people find products they’d like to use.
So one of their biggest revenue generators is product advertisement.
Their latest research shows how they used generation models to create Pinterest Canvas, a model which is able to take a target product image and generate various backgrounds and style while keeping the product intact.
How?
Using their own large custom image dataset (even after excessive filtering of their visual data, they were left with 1.5 billion high-quality text-image pairs), they trained a base generation model which is capable of creating high quality images from text.
They then fine-tuned that model to be able to segment a product from an image and recreate its background.

To create a personalized product image generation model, Pinterest used a combination of different embeddings across text and images before merging them in their own text-to-image generation model Pinterest Canvas. Source: Pinterest Engineering Blog.
People who would like to advertise their products on Pinterest are now able to alter their product photography with different styles to appeal to those with different interests.
3. Answer.AI’s plethora of resources and learnings
Answer.AI is a newish company with the goal of shipping useful AI products.
As a small AI developer, this is inspiring to me.
And so far, they’ve been delivering.
I’ve been reading their various blog posts and learning the potential of small embedding models (answerai-colbert-small-v1 shows that small doesn’t mean un-useful!), how to create things on the web without the complexity of the web (FastHTML) and how you can efficiently fine-tune Llama on a single GPU (with DoRA - Weight-Decomposed Low-Rank Adaptation).
For some idea on how research and development is done at Answer AI, I’d highly recommend checking out the following:
- How Answer.AI created a 33M (33 million) parameter embedding model capable of running on CPUs that outperforms models 3x its size.
- How to fine-tune Llama 3 on a single GPU using DoRA.
- How to build web applications in pure Python using FastHTML (which builds on top of htmx, a new-ish web framework focused on simplicity and web standards).
- Bonus: [Podcast] Jeremy Howard on Latent Space talking all things AI and how to run a small research & development company (August 2024).
If you want to do AI research & development, working on small but useful projects, I’d highly recommend seeing how Answer do it and copying their approach (e.g. build in public).
4. Meta releases a series of guides on how to adapt and fine-tune LLMs to your own problems
With open-source LLMs gaining more and more traction, it’s starting to make more and more sense to customize them to your own problems.
This can be done quite well with larger LLMs such as GPT-4o, Claude and Gemini using in-context learning (e.g. putting examples into your prompts so the LLM can mimic them).
However, these models are closed-sourced and require your data (often one of your business’s most valuable resources) to be sent to a third party for processing.
The solution?
Fine-tune an open-source LLM to suit your needs!
And Meta’s three part series can help you out:
- Part 1: Methods for adapting large language models — Discusses five main ways of customizing LLMS, including, pretraining (very compute intensive), continued pretraining (quite compute intensive), full fine-tuning and parameter-efficient fine-tuning (PEFT), retrieval-augmented generation (RAG) and in-context learning (ICL).
- Part 2: To fine-tune or not to fine-tune? — Discusses when fine-tuning should be a viable option, including use cases such as, customizing tone, style and format, increasing accuracy and handling edge cases (e.g. show an LLM 100 labelled examples of your specific problem for potentially dramatic increases in performance), addressing underrepresented domains, cost reduction (fine-tune a smaller model to perform a task by showing it the outputs of a larger model) and enabling your model to perform new tasks and abilities (e.g. being a better judge or increasing its context window).
- Part 3: How to fine-tune (focus on effective datasets) — Discusses how to think about creating a dataset to fine-tune your LLM. Quality seems to be most important, as the example they give is a few thousand curated samples can perform better than a larger dataset of 50K+ machine-generated samples. For harder tasks, more quality samples is also generally better. The OpenAI fine-tuning documentation states that improvements are generally seen with 50-100 examples and recommends starting with 50 well-crafted examples to see if an LLM responds well to fine-tuning.
5. Dropbox shows how turning everything into text can help with search
Dropbox is one of the most popular pieces of software on the planet.
Their mission is to store and sort all of your files.
But as files grow (in size and numbers), this is no easy feat.
However, AI makes this easier.
In their recent tech blog, the Dropbox team stated that one method for making searching better is to turn all files to text.
Even for video files, you can go from video -> audio file -> audio transcript -> text -> embeddings.

Dropbox makes over 300 file types searchable with text by… turning them into text! And then embedding the text to make it semantically searchable. Source: Dropbox Tech Blog.
By doing this, you enable semantic searching (e.g. searching across embeddings) across a wide range of files.
They then use the results of these searches to power AI-based features such as Q&A with sources (answer questions based on your own documents) and summarization.
I also liked their text-chunking technique of collecting semantically similar chunks by clustering them with K-means. This means groups/paragraphs of texts in a document which have similar meaning can be returned together rather than sequentially.
6. Transformers Explained (visually and interactively)
One of my favourite websites for explaining how Convolutional Neural Networks (CNNs) work is CNN Explainer.
And now the same people have created Transformer Explainer!
And my gosh is it fun to use.
If you’re looking for an excellent resource to learn about the Transformer architecture (the same neural network architecture powering ChatGPT and similar LLMs), be sure to check it out.

Example of Transformer Explainer running in the browser showing the computations of the multi-head self attention operation. Source: Transformer Explainer website.
7. PyTorch introduces FlexAttention API capable of handling many different implementations of attention
Since the initial release of the attention mechanism (one of the main building blocks of the Transformer architecture), there have been many iterations of it.
And the torch.nn.attention.flex_attention module hopes to help with both existing methods and newer methods.
The PyTorch team have also released a attention-gym repo on GitHub to help with learning examples.
8. An explosion of open-source VLMs (Vision-Language Models)
VLMs are models which merge the vision and language modalities (see VLMs explained as mentioned in the July 2024 edition of AI/ML monthly).
With all the movements in the open-source LLM world, it’s good to see that open-source VLMs are thriving too.
Namely:
- HPT 1.5 Edge (Apache 2.0 license) is a smaller VLM with incredible performance capable of running on-device (though I always take these on-device claims with a grain of salt because unless you share an example to get your model running on-device, how can it be tested?). Combines SigLIP vision encoder with Phi-3-mini LLM.
- BLIP-3 models (also called xGen-MM, Apache 2.0) is a continuation of the incredible BLIP series from the Salesforce AI team. Combines Phi-3-mini and SigLIP vision encoder (they also tested DFN, another CLIP-like model but found that SigLIP performed better, see section 7.1 in the paper).
- Idefics3-Llama (Apache 2.0 license) combines SigLIP with Llama-3.1-8B-Instruct and is from the Hugging Face team. The highlight of this model for me was the paper that came with it. Building and better understanding vision-language models: insights and future directions was an absolute joy to read and goes through many of the details of what it takes to build a modern VLM.
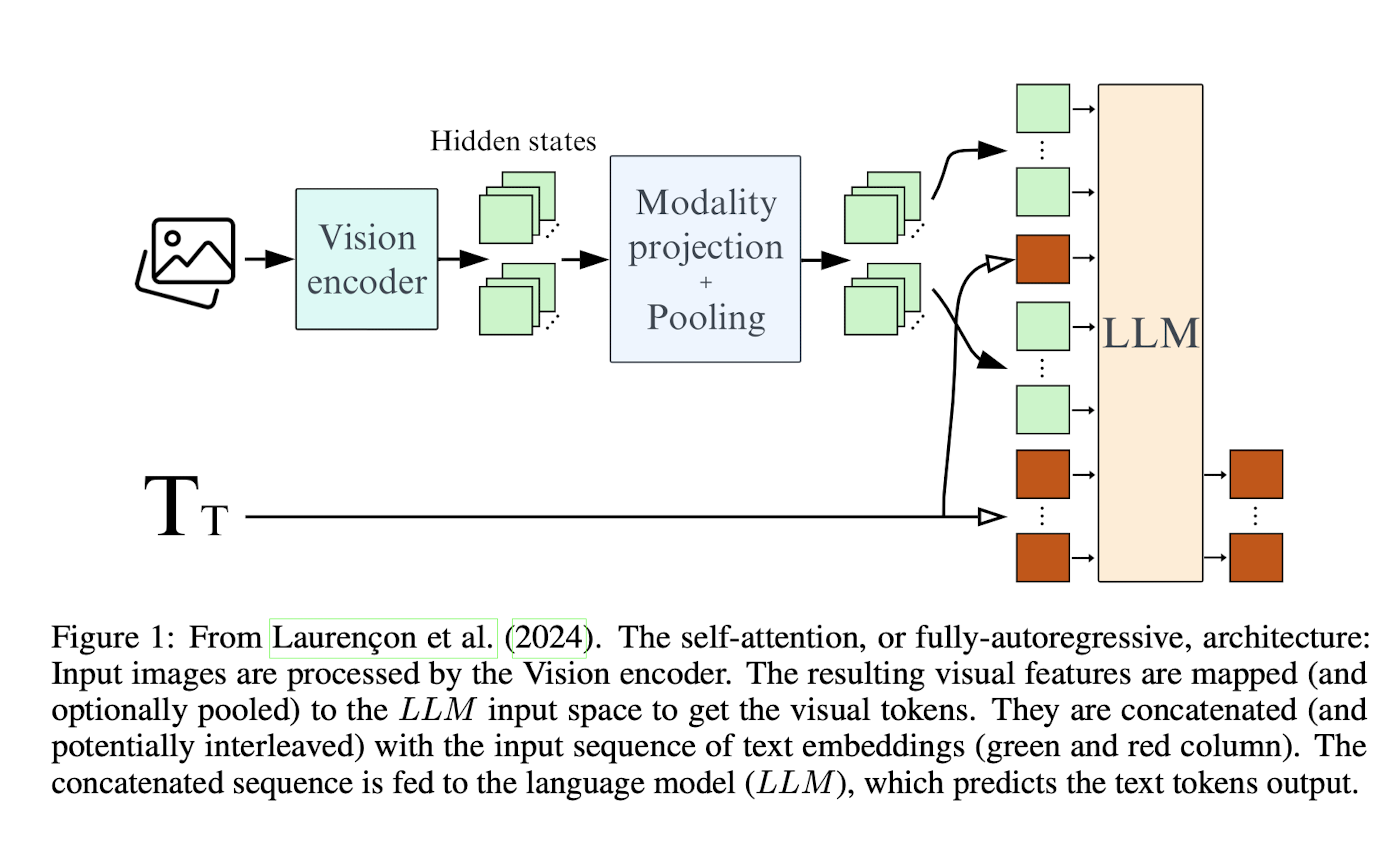
General architecture overview of many modern VLMs. A vision encoder (e.g. SigLIP) is used to encode images and a text encoder (e.g. the embedding layer of Llama-3.1-8B) is used to encode text. These encodings are then fused/concatenated and then fed to the rest of the LLM to decode the outputs tokens. Source: Idefics 3 paper.
- InternVL2.0 from OpenGVLab is a wide-ranging collection of VLMs consisting of several different sizes from 2B to 108B, with the Pro version performing on-par or better than proprietary models such as GPT-4o and Claude 3.5 Sonnet.
- Qwen2-VL is a series of VLMs from the Alibaba Cloud research group called Qwen. Their latest release includes a range of models from Qwen2-VL-2B-Instruct and Qwen2-VL-7B-Instruct (both Apache 2.0) to Qwen2-VL-72B (available via API). Their models perform at par or better than all equivalent models at each size (the biggest model outperforms GPT-4o and Claude 3.5 Sonnet on almost every visual task). Read the announcement blog post with results and more on their website.
- Microsoft launches the Phi-3.5 series of models including Phi-3.5-mini-instruct (a 4B LLM), Phi-3.5-vision-instruct (a 4.2B VLM, e.g. a vision encoder + Phi-3.5-mini-instruct) and Phi-3.5-MoE (16x3.8B parameters with 6.6B active parameters, MoE stands for “mixture of experts”). These models are built on a collection of synthetic and real datasets with a focus on high-quality, reasoning-dense data. I’ve done a handful of tests on these and so far, the vision version of Phi-3.5 performs quite well for its size, all able to run a local single GPU.
Phew!
What a month in the VLM space!
One thing I noticed is the trend of using SigLIP as a vision encoder.
I use SigLIP almost every day and it’s an incredible model.
Bonus: For those wanting to learn more about it, I’d highly recommend this talk from one of the authors (Lucas Beyer, the same Lucas from the ViT vs. CNN post above).
A quote from the talk that stood out to me was:
The more precise your text is, the higher your matching score.

Notice how the matching score goes through the roof when you describe the image with precision. Something to keep in mind if you’re using the SigLIP model. Source: Lucas Beyer SigLIP talk on Cohere YouTube Channel.
This was referring to image-text similarity matching with SigLIP. If you can describe your image visually with text, chances are, SigLIP can match it correctly. This is a really powerful technique for things such as zero-shot labelling and clustering.
9. More open-source LLMs and image models
- NVIDIA show how you can use model pruning (removing less important branches of a neural network) and distillation (teaching a smaller model with a larger one) to turn a 12B parameter model into a 8B parameter model without losing significant performance. Specifically, they turn Mistral-NeMo-12B into Mistral-NeMo-Minitron-8B, saving nearly 2x the compute compared to training from scratch.
- NVIDIA also show how you can use pruning and model distillation to turn Llama-3.1-8B into Llama-3.1-Minitron-4B (about half the parameters) with minimal performance loss. They also released a paper detailing their 10 principles for creating compact models via pruning and distillation.

NVIDIA’s best practices for compressing a bigger LLM into a smaller LLM. Source: Compact Language Models via Pruning and Knowledge Distillation paper.
- Black Forest Labs release two open-source text-to-image generation models,
FLUX.1-schnell(Apache 2.0) andFLUX.1-dev(non-commercial). From my brief experimenting, these are incredibly good models. They’re from the team who created the original Stable Diffusion models, you can read their launch post on their blog. - Stability AI releases
stable-fast-3denabling fast 3D asset generation from a single image. - IDEA-Research releases
Grounded-SAM-2enabling automatic segmentation labelling by combining Florence-2 (for text-based captions, see AI/ML monthly June 2024 for more), GroundingDINO (for boxes) and SAM-2 (for segmentation masks).
10. Tutorials, Guides + Misc
- [Paper] Are Emergent Abilities in Large Language Models just In-Context Learning? — Researchers find that the “emergent” capabilities of LLMs are “are not truly emergent, but result from a combination of in-context learning, model memory, and linguistic knowledge.”
- [Video Tutorial] Low-level technical talk of how LLMs work by Daniel Han.
- [Video Tutorial] Replicating PaliGemma (a VLM) from scratch with PyTorch by Umar Jamil.
- [Video Tutorial] Build a football analysis project using computer vision by Piotr Skalski from Roboflow.
See you next month!
What a massive month for the ML world in August!
As always, let me know if there's anything you think should be included in a future post.
In the meantime, keep learning, keep creating, keep dancing.
See you next month,
Daniel
By the way, I'm also an instructor with Zero To Mastery Academy teaching people Machine Learning & AI in the most efficient way possible. You can see a few of our courses below or check out all Zero To Mastery courses.
















