


18th issue! If you missed them, you can read the previous issues of the Machine Learning Monthly newsletter here.
Daniel here, I'm 50% of the instructors behind the Complete Machine Learning and Data Science: Zero to Mastery course and our new TensorFlow for Deep Learning course!. I also write regularly about machine learning and on my own blog as well as make videos on the topic on YouTube.
Welcome to the 18th edition of Machine Learning Monthly. A 500ish (+/-1000ish, usually +) word post detailing some of the most interesting things on machine learning I've found in the last month.
Since there's a lot going on, the utmost care has been taken to keep things to the point.
What you missed in June as a Machine Learning Engineer…
My work 👇
Video version of this post can be watched here.
The Zero to Mastery TensorFlow for Deep Learning course has launched!
Eager to learn the fundamentals of deep learning?
Like to code?
Well, this course is for you.
It's entirely code-first. Which means I use code to explain different concepts and link external non-code first resources for those who liked to learn more.
I’m so pumped for this release, it’s the biggest thing I’ve ever worked on! I’d love if you checked it out:
- Sign up on the Zero to Mastery Academy for the full course
- View all of the course materials on GitHub (more to come)
- Ask a question on the course GitHub Discussions tab if you’d like to know more
- See and try the first 14-hours of the course on YouTube
- 📖 New: Read the entire course materials as a free (and beautiful) online book!
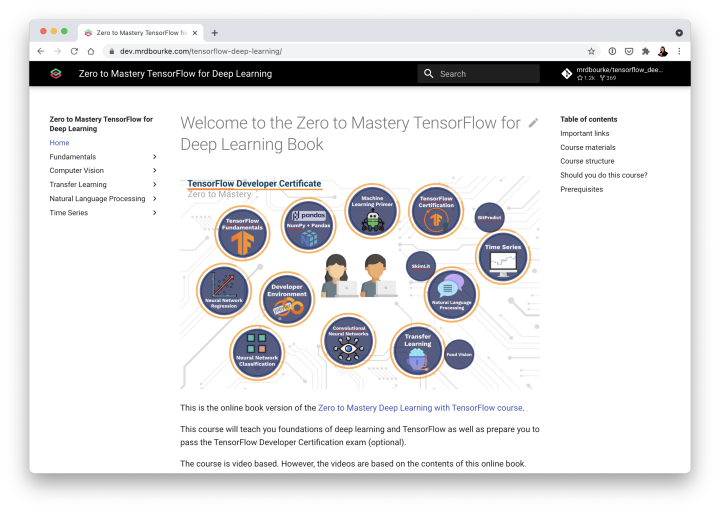
Jupyter Notebooks (where all the course materials live) can be hard to load/read/search. So now all of the course Zero to Mastery TensorFlow for Deep Learning materials are available as a beautiful online and searchable book!
From the internet 🕸
Uber's Journey Toward Better Data Culture From First Principles
What it is: A blog post by the Uber engineering team which talks about how they've created a data-first business using the following principles:
- Data as code — How did it get created? How did it get changed? When did it get retired? All of these questions should be asked and tracked of data just like they do with code.
- Data is owned — Got a problem with a dataset? Who should you go to talk to?
- Data quality is known — Poor data = poor results. Owning data is the first step, taking care of it is the next.
- Organize for data — Every team should aim to have someone with skills for every part of the data engineering stack, failing to do so can result in unnecessary bottlenecks.
Why it matters: Software 2.0 (programming data instead of code) is slowly gaining momentum. Especially for companies such as Uber who thrive on data. If your company is thinking about exploring leveraging data, it'd be wise to check out how one of the veterans (veteran is used loosely here since although Uber is around ~12-years old, they would be considered an elder in the data-first space) do it.
Text-based Video Editing (research paper/demo)
What it is: Record a video. Screw something up, like pronouncing the word schnapps wrong. Don't bother re-recording though, just transcribe the audio and edit the text, then get a new video back in 40-seconds. What? Seriously? Yes.
That's what researchers from Stanford have done. Take 2-3 minutes of spoken video from a target person, run a few self-supervised algorithms over the top, cut out the bad parts, leave in the good parts, and you're done (I'm summarising here but it's actually quite close).
Check out the video demo.
Why it matters: Every so often something will come out of the world of ML and blow me away. This was one of those things.
One of the authors reached out to me asking if it's something I'd use. My immediate reaction was yes. But then I tried to think of where and when. And I couldn't. Because it's such a paradigm shift in how I would usually create such a video edit. Usually I'd just cut the errors out, or do another take. I'd never even thought of generating new video by just typing into a text box.
Right now, the research is still research but Descript is a company looking to do something similar with their transcription/audio/video editing tool (which I've also used in the past).
See the following for more:
- Check out the project website
- Read the paper
- Watch the video demo
GPT-3 came for writers, now it's coming for coders via GitHub Copilot
What it is: It's all starting to make sense. Microsoft bought GitHub, Microsoft partnered with OpenAI, OpenAI partners with GitHub to make a super-charged code-completion tool for VSCode, a Microsoft product.
We've cracked the code!
And it appears GitHub's Copilot has too.
GitHub Copilot leverages OpenAI's Codex (cool name), which looks like a GPT-3 variant trained on public GitHub repositories to complete code snippets based on natural language.
Right now, the tool is in an invite-only beta but if it turns out to be as good as some of the demos look, all of our code is going to be soaring high!
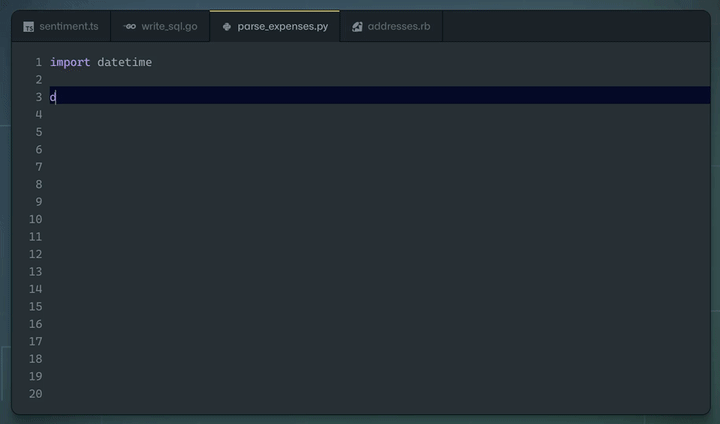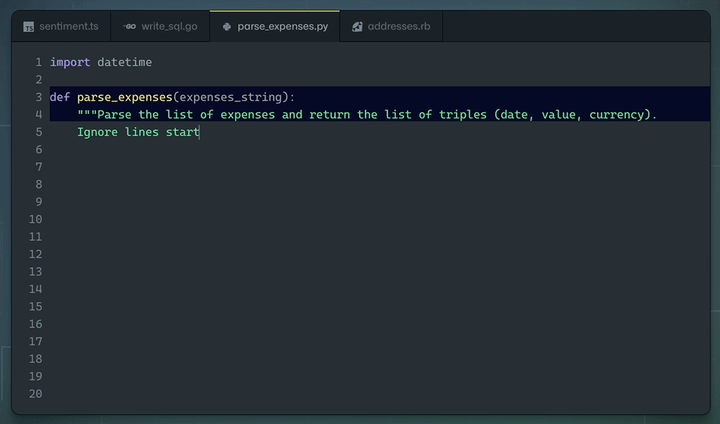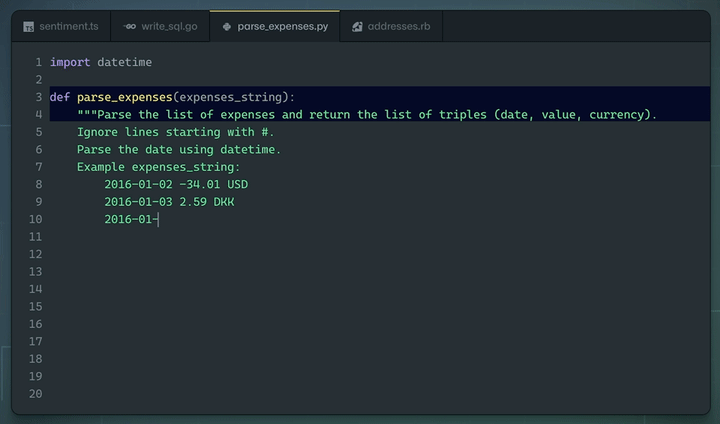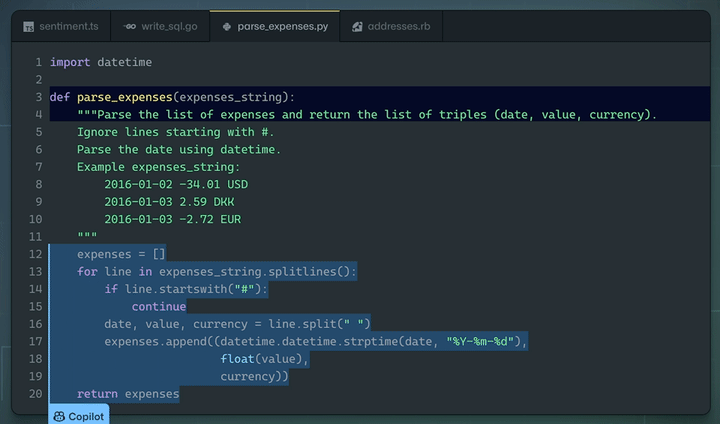
Demo of GitHub Copilot in action writing a Python function based on a docstring as instruction. Source: GitHub Copilot homepage.
Why it matters: Will this replace coders? It's hard to tell. I don't think so. Autocompletion is programming as much as text suggestions is writing. It'll be another tool in the programmer's toolbox.
Something you'll be able to use to augment your workflow, for more common functionality, you'll be able to lean on Copilot but you'll still need to design the overall workflow yourself.
And since Copilot will likely learn your preferences over time, you'll probably learn to "play" it, just like you would learn to play the guitar (the more descriptive your docstring, the better the code output).
It's also another step in the direction of generative machine learning with GPT-3-style natural language algorithms, CLIP and DALL•E for images, now Codex for code. Perhaps we'll see a music generator next? "Computer, play me a Bach composition with Lana Del Rey singing over the top".
Sign up for the waitlist on the GitHub Copilot homepage.
Cracking the Machine Learning Interview Book
What it is: Applying for a job and getting a job is a skill in itself. But once you get a job, you stop using that skill, because, well, now you've got a job.
And how to get a job is one of those things which is almost impossible to teach. Why? Because unlike code, which usually works or it doesn't. The steps you take for getting a job could be different for every job you apply for.
One company might require you to have an advanced degree, another company might not require any degrees but you better be able to code a machine learning algorithm from scratch by hand on a whiteboard (if an interview requires you to actually do this, all the best).
A whole book could be written on the topic.
Guess what?
Lucky for us, it has.
The amazing Chip Huyen has put together her vast experience from machine learning startup interviewing to large scale company interviewing to machine learning teaching, everything into an online book called The Machine Learning Interviews Book.
If you've put in the effort to learn machine learning skills and now want to get paid for those skills, read this book.
Why it matters: I'm so happy. So so so happy. When people ask me how do I get a job in machine learning, I usually tell them "I don't know" and then follow up with "but my best advice is 'start the job before you have it'". From now on, I'm still going to say that. But I'm also going to link them to Chip's book.
Some of my favourite sections include:
- 1.1 Different machine learning roles — the list has grown over the past few years, from data scientist to data engineer to machine learning engineer to research engineer, what's the difference between them all?
- 4. Where to start, how do I need? — Machine learning is a vast field. And like anything worthwhile, becoming skilful in it takes time (more than 3 months).
- Appendix B: Building your network — Most jobs come from referrals, internal employees recommending their friends or people they know. Yeah, so how do you get friends internally? Share your work and talk to others who do the same.
How Tesla are inching towards full self-driving (Andrei Karpathy CVPR 2021 workshop)
What it is: CVPR = conference on computer vision and pattern recognition. And Andrej Karpathy is Tesla's head of AI.
Tesla are the world leader in self-driving cars.
How?
That's what Karpathy reveals in this talk. From how they approach data collection (now vision only), to data preprocessing and storage (over 1.5 petabytes), to machine learning infrastructure (think the 5th largest supercomputer in the world), to machine learning algorithm design, to data programming (software 2.0) and more.

Training full self-driving algorithms is no joke. Tesla's supercomputer cluster has 5760 80GB GPUs! Source: Andrej Karpathy (Tesla): CVPR 2021 Workshop on Autonomous Vehicles
Why it matters: I love seeing talks like this. One of the world leaders in a field revealing their tricks of the trade. Of course, not everyone will be able to replicate them but at least knowing what's worked for them can give others an insight into how they might go about building something similar.
What's clear to Tesla's leadership in self-driving is the vertical integration of the stack, more specifically, they own everything from: data collection → compute → chip design → car design → software design. The whole thing turns into one giant feedback loop, a data flywheel.
Hit me baby two more time (series analysis and forecasting libraries)
What it is: Here's the scenario. You're working on a time series analysis problem. And you're wondering how the best do it?
How do companies like Facebook and LinkedIn analyse their time series data?
How do they make forecasts on what to show on their timelines and when?
Well, have I got some good news for you!
Facebook and LinkedIn have both just released new Python-based libraries for state-of-the-art time series analysis and forecasting.
Facebook's Kats library gives you access to forecasting, detection (analysis), feature extraction and embedding tools and more.
LinkedIn's Greykite library offers a very similar setup for forecasting, anomaly/outlier detection, exploratory analysis, feature extraction and more.
Why it matters: Instead of hand-coding your own algorithms, why not start off with ones crafted by the best and adapt them to your problem?
And if they don't work, well, then you can start heading towards the custom route.
Find the code for both on GitHub:
All kinds of data augmentation with AugLy by Facebook
What it is: A data augmentation library that supports over 100 different kinds of data augmentation for text, image, video and audio data.
From adding text over images (meme style) to jumbling up text, AugLy's packed with everything a data augmentor (I made this word up) could want.
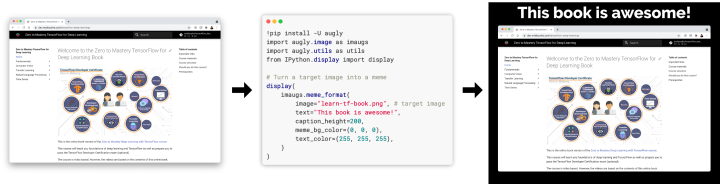
Example workflow of AugLy, have an input image, write a few lines of code, get an augmented image as output.
Why it matters: Data augmentation often improves the robustness of an AI model (its ability to adapt to unseen forms of data). AugLy provides an easy-to-use Python interface for adjusting various forms of data to help AI models capture data which have been changed to avoid content filters. For example, someone hiding a copyrighted image in the form of a meme to escape an automatic detection system on Instagram.
The fantastic four (rapid fire resources) 🦸♂️
2 x MLOps
- The outstanding MLOps course by Made with ML has been completed. Goku Mohandas has absolutely outdone himself here. Putting some of the most high quality resources on all of the pieces of the puzzle which go around building a machine learning model (data collection, labelling, deployment, monitoring and more).
- MLOps.toys is a collection of curated MLOps tools for all kinds of use cases from data versioning to model serving to experiment tracking.
2 x Beautiful blog posts
- Training Compact Transformers from Scratch in 30 Minutes with PyTorch. Since their inception, Transformer architectures have been notorious for the large amounts of data they require for training. However, in the article above, a group of researchers from the University of Oregon and Picsart AI Research describe their latest innovation, Compact Transformers — a version of the Transformer architecture you can train on a single GPU!
- Applied NLP Thinking by Ines Montani. Co-founder of Explosion.ai and core developer of the spaCy NLP library, Inex Montani outlines the thought process between NLP research (discovering new NLP techniques) and applied NLP (putting NLP techniques into practice). One of my favourites is "finding the best trade-offs". For example, sometimes the best performing model in a research setting (highest accuracy) can't work in a production setting because it's too large (slow to compute) — sometimes bigger isn't always better.
See you next month!
What a massive month for the ML world in June!
As always, let me know if there's anything you think should be included in a future post. Liked something here? Tell a friend!
In the meantime, keep learning, keep creating, keep dancing.
See you next month,
Daniel
PS. You can see also video versions of these articles on my YouTube channel (usually a few days after the article goes live).
By the way, I'm a full-time instructor with Zero To Mastery Academy teaching people Machine Learning in the most efficient way possible. You can see a couple of our courses below or see all Zero To Mastery courses by visiting the courses page.













