


6th issue! If you missed them, you can read the previous issues of the Machine Learning Monthly newsletter here.
🤖Welcome to Machine Learning Monthly... one of the best ways to get started in the industry. The first part of this series is about solving problems in machine learning. The second part is about how to use machine learning to solve problems in machine learning. In this post, I'll introduce you to a number of new machine learning algorithms that I've been working on for the last year or so. I'll also cover some of the more common problems and techniques that you'll find as you learn about machine learning. I will also be discussing the various problems that you'll encounter in machine learning, and the ways that you can learn them in this series.
Woah... The above paragraph was completely artificially generated. I fed a machine learning algorithm known as GPT-2 (check out #2 below) the words "welcome to machine learning monthly" and it completed the rest.
Anyway, back to people generated words (I promise).
Hey everyone, Daniel here, I'm 50% of the instructors behind the Complete Machine Learning and Data Science: Zero to Mastery course.
This is the sixth edition of Machine Learning Monthly. A 500ish word post detailing some of the most interesting things on machine learning I've found (or made) in the last month.
Let’s get into it.
What you missed in June as a Machine Learning Engineer…
Video 📺 > Blog 📝?
Machine Learning Monthly is typically a written post but I thought it would be fun to do a video version of the post as well. Check out both versions below and let myself and the ZTM team know which format you like better!
My posts
- “How can a beginner data scientist like me gain experience?” — Manuela emailed me this question and I replied with a few things I think you’ll find useful. The main one being: start the job before you have it.
- How I passed the TensorFlow developer certification (and how you can too) — During May I set myself up with a curriculum to sharpen some of my TensorFlow skills. All with the goal of taking the TensorFlow developer certification at the start of June. I took the exam and passed. So I put together an article (and video) of resources and techniques that I used to do it.
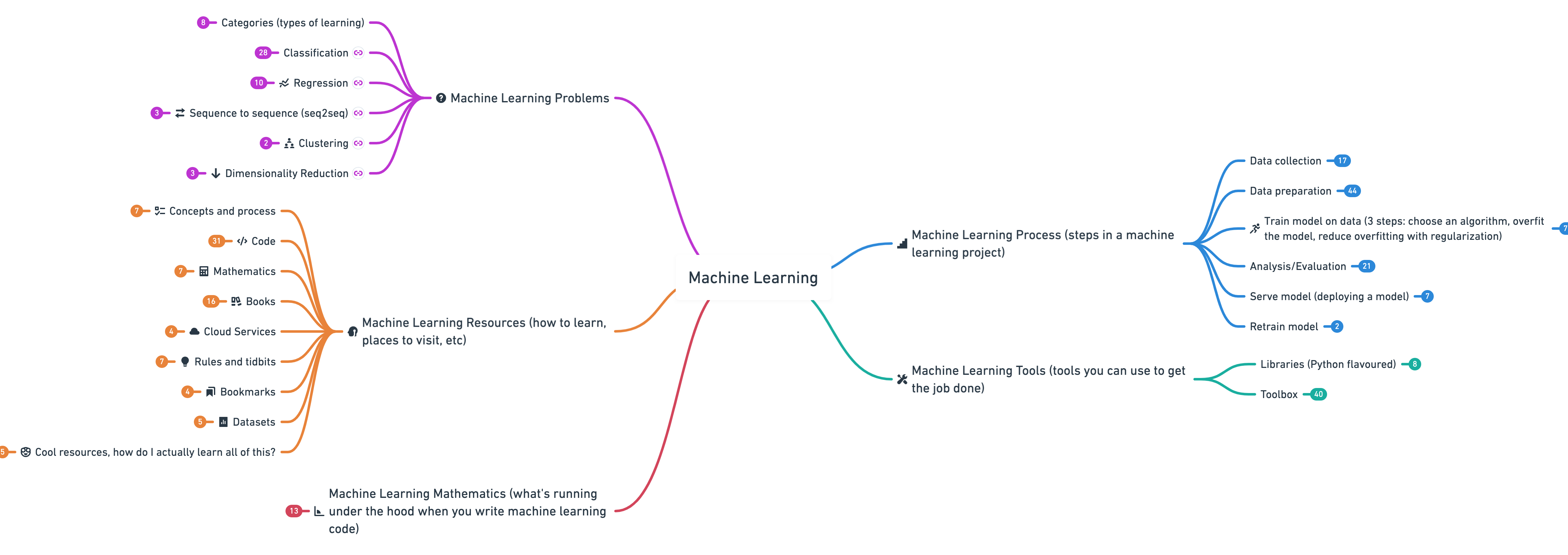
1. Machine Learning Roadmap 2020
When starting out machine learning, it can be hard to connect the dots. From the different machine learning tools, to the process of working on a machine learning project, to the different kinds of evaluation metrics you need for each problem.
The Machine Learning Roadmap 2020 (actually a big interactive mind map) connects many of the most important concepts, as well as resources for learning more about each of them.
More specifically, it covers (broadly):
- Machine learning problems — how to diagnose a machine learning problem.
- Machine learning process — once you’ve identified a machine learning problem, what steps can you take to solve it?
- Machine learning tools — what tools are available to you to solve the problem?
- Machine learning mathematics — since machine learning is largely using math to find patterns in numbers, what subfields of math are running under the hood of the machine learning algorithm you‘re calling?
- Machine learning resources — alright, so the above has sparked your curiosity, how do you learn these things? This part has you covered.
I’m so excited for this. I think you’ll love it.
PS. Stay tuned for a full 2.5 hour video version coming soon which will premiere on the Zero To Mastery Youtube Channel. Subscribe now so that you don't miss it!
2. aitextgen — Leverage OpenAI's GPT-2 architecture to generate text
I spent an hour or so playing around with this. You can get up and running in under 5-minutes on Google Colab (just follow the instructions in the GitHub repo).
Max Woolf makes some really cool things and this might be my favourite yet.
Out of the box, aitextgen leverages OpenAI's 124M parameter version of GPT-2 (for context, the biggest one available is 1.5B parameters) to take in a seed, such as, "welcome to machine learning monthly" and then it artificially generates text up to your desired length (using the max_length parameter).
You can even train the model on your own text to generate something flavoured with your style (perhaps it could read all of your old blog posts and generate a new one for you?).
As text generation gets better and better, it'll be an interesting time when you could effectively run a social media account with purely AI-generated text.
3. Using AI to play like Bach
As if generating text with AI wasn't enough to fuel your artistic dreams. How about using AI to generate music in the style of Bach (a famous German composer)?
Last year, Google did just that with their Google Doodle. They trained a machine learning model (called Coconet) on 306 of Bach's compositions and created an interactive demo where you can enter your own music notes and have them artificially harmonized (turned into something that sounds pretty good).
I'm liking this theme.
AI generated art is definitely becoming a thing. If you never fancied yourself a musician but you can code, now you can write code to play the music for you.
The blog post that went along with it is also truly worth the read.
4. Data science: expectations vs. reality
Dan Friedman attended a 12-week data science bootcamp in 2016, during which ML & AI was everywhere in the news. However, after some experience in the field, he found his expectations didn't meet reality.
In particular, some takeaways include:
- People don't know what "data science" does (it's more than just running machine learning algorithms)
- Most ML projects don't make it into production
- Data & data infrastructure tools are lacking (data in industry is different to data you find in books & Kaggle competitions)
The last two are very real. Building a model these days is becoming very approachable, however, getting it into people's hands is the real challenge.
Enter, MLOps.
5. What the hell is MLOps anyway?
So you want to get your machine learning model out into the world?
Well then, you'll probably want to familiarize yourself with MLOps (short for machine learning operations). If you're familiar with DevOps, MLOps is the same but with machine learning thrown in the mix.
In essence, MLOps is all the things you need around your machine learning model so users can interact with it.
It's a combination of: a data pipeline (a way to collect and prepare data), a machine learning model (the fun part) and a way to serve that machine learning model (a web or mobile application or API).
A few years ago, deploying a machine learning model was like black magic. Some (outside of large tech companies) had heard of it and even less had done it.
Now though, the tools in the space of getting your machine learning creation to the world are growing and the good thing is, Chip Huyen has written a fantastic blog post reflecting on what she learned by going through 200+ (yes, two-hundred plus) of them.
Check it out and use what you learn to get your machine learning models in the hands of people around the world.
6. One neural network to rule them all!
(not really, just a really cool way to train a single neural network and have it be optimised for multiple device types).
This is actually a really important piece of research.
Usually, to have the same machine learning model deployed across multiple device types (think smartphone, desktop PC and microcontroller), you'd need to train a separate model for each one.
This practice of training a separate machine learning model for each device type, especially when they're all learning similar things, turns out to be incredibly wasteful (perhaps surprisingly, computing power doesn't magically grow on trees, it burns carbon and releases emission).
Not anymore. The once for all network (codenamed OFA) is a training paradigm which allows you to train a neural network once and have it automatically adapt itself (during training) for different devices.
The explanation the researchers give is worth reading itself, let alone the outstanding work they've created.
7. All of the matrix calculus you need for deep learning
Jeremy Howard (the creator of fast.ai) decided he needed to know more about the matrix calculus which works under the hood of deep learning.
So he and his colleague Terence Parr wrote a book about it.
That's the trick. If you want to know something about something, write a book about it.
And if you want to brush up your matrix calculus (and your deep learning from scratch skills), The Matrix Calculus You Need For Deep Learning book is for you.
8. Can AI play Minecraft?
A new challenge has kicked off on AI Crowd. The goal? Teach an AI system to find a diamond in Minecraft.
Now, you see, I've never played Minecraft and never intend to. But this kind of challenge excites me.
If you want to get hands-on with a reinforcement learning project (if you do well, you'll probably be ripe for a job at OpenAI or DeepMind), check out the 2020 MineRL challenge.
9. YOLOV4 — The state of the art real-time object detection model, You Only Look Once, is back (for a 4th time)
If you ever want to announce that you're launching a state of the art machine learning algorithm, Aleksey Bochkovskiy's Medium article should be your reference point.
The first paragraph says enough.
"Darket YOLOv4 is faster and more accurate than real-time neural networks Google TensorFlow EfficientDet and FaceBook Pytorch/Detectron RetinaNet/MaskRCNN on Microsoft COCO dataset."
This just goes to show, determined, small-group researchers can take on the likes of Google and Facebook.
10. End-to-end object detection with Transformers
Speaking of object detection, Facebook just did it with a new style (well, a different model than what's usually used).
Transformers (a machine learning architecture) have been breaking all kinds of records in the NLP (natural language processing) space over the past year. Now they're making their way into computer vision.
DETR (short for detection transformer) is a transformer-based object detection algorithm which gets results equivalent or higher than previous state of the art (not to be confused with YOLOV4 though, YOLOV4 is real-time, DETR isn't).
Is the transformer architecture the universal architecture (a model that can perform well on all kinds of problems)?
Perhaps.
If you'd like a primer on Transformers, I'd suggest...
10.5 The transformer explained by nostalgebraist
You'll probably see more about the Transformer architecture in the near future. So it's worth figuring out what it does.
The Transformer "explained" post does a great job of giving you an overview. It also links to several helpful references to find out for more.
See you next month!
And that's it for June.
As always, let me know if there's anything you think should be included in a future post. Liked something here? Send us a tweet.
In the meantime, keep learning, keep creating.
See you next month,
Daniel www.mrdbourke.com | YouTube
PS. Last reminder to stay tuned for the Machine Learning Roadmap video, it should be out in the next week or so! Subscribe to the Zero To Mastery Youtube Channel so that you don't miss it.
By the way, I'm a full time instructor with Zero To Mastery Academy teaching people Machine Learning in the most efficient way possible. You can see a couple of our courses below or see all Zero To Mastery courses by visiting the courses page.













