


51st issue! If you missed them, you can read the previous issues of my monthly A.I. & Machine Learning newsletter here.
Hey there, Daniel here.
I’m an A.I. & Machine Learning Engineer who also teaches the following beginner-friendly machine learning courses:
- Complete A.I. Machine Learning and Data Science Bootcamp: Zero to Mastery
- TensorFlow for Deep Learning: Zero to Mastery
- PyTorch for Deep Learning: Zero to Mastery
- [NEW] Project: Build a custom text classifier and demo with Hugging Face Transformers
- [NEW] Machine Learning with Hugging Face Bootcamp
I also write regularly about A.I. and machine learning on my own blog as well as make videos on the topic on YouTube.
Since there's a lot going on, the utmost care has been taken to keep things to the point.
Enough about me! You're here for this month's A.I. & Machine Learning Monthly Newsletter.
Typically a 500ish (+/-1,000ish, usually +) word post detailing some of the most interesting things on machine learning I've found in the last month.
Here's what you might have missed in March 2024 as an A.I. & Machine Learning Engineer... let's get you caught up!
My Work 👇
Two video tutorials from me this month:
1) Build a simple local RAG (Retrieval Augmented Generation) step-by-step (6-hours)
Code your very own RAG pipeline to improve the generations of LLMs line-by-line.
In the video we build NutriChat, a RAG-based system to chat with a 1200 page nutrition textbook PDF using Google’s recent Gemma LLM. And the entire pipeline runs locally (or in Google Colab).
Get the code on GitHub.
2) Run a local version of ChatGPT on your NVIDIA GPU with Chat with RTX (video walkthrough)
NVIDIA recently released an app called Chat with RTX. It’s designed to be ChatGPT-like app that works entirely on your local NVIDIA GPU. You can even upload your own documents and chat with the model and have it reference those documents.
From the Internet 👇
1) How Apple bought transcriptions to Podcasts with a custom evaluation metric
Apple recently updated the Podcasts app with transcriptions. You can now listen to podcast episodes alongside readable transcriptions.
They also released a post on their machine learning blog about the workflow of creating a dataset to measure the performance of the transcription models.
Instead of using WER (word error rate), they used HEWER (human evaluation word error rate). The former takes into account every error (including “ah”, “umm” etc) whereas the latter focuses on errors which make the transcript unreadable or have a different meaning.
Often transcripts will have a seemingly large WER but a lower HEWER (the script is still readable).
The blog shows a sensational example of where a common academic evaluation benchmark (WER) may not be entirely suited to an actual production deployment.

Left: Transcript of Apple Podcast episode from the Hungry podcast. Right: Apple’s custom evaluation metric for making sure transcripts are still human-readable. Source for right image: Apple’s Machine Learning Blog.
2) Croissant is a new open-source metadata framework for ML datasets 🥐
Croissant combines metadata, resources file descriptions, data structure and default ML semantics into a single file. It works with existing ML datasets to make them easier to find, use and support with various tools.
If you’re creating an open-source dataset for ML (or even a closed source dataset), you should consider pairing it with the Croissant framework.
It’s backed and built by engineers from Google, Meta, Hugging Face, DeepMind and more.
And it can be used directly with TensorFlow Datasets (TFDS) to help load data into frameworks like TensorFlow, PyTorch and JAX.
See the code on GitHub and TensorFlow Datasets documentation.
import tensorflow_datasets as tfds
builder = tfds.dataset_builders.CroissantBuilder(
jsonld="https://raw.githubusercontent.com/mlcommons/croissant/main/datasets/0.8/huggingface-mnist/metadata.json",
file_format='array_record',
)
builder.download_and_prepare()
ds = builder.as_data_source()
print(ds['default'][0])3) Magika is an open-source tool to detect file content types with deep learning
Trained on millions of files using Keras, Magika is a fast and lightweight (1MB) model that can detect file types in milliseconds.
A similar model to Magika is used in Google to detect different file types and route them appropriately in Gmail, Drive and more. Every week it looks at hundreds of billions of files to make sure they’re the correct kind.
Magika has got remarkable performance with an average of 99%+ precision and recall across 120+ file types.
It is available under the Apache 2.0 licence and is easy to get started with.
Get the code on GitHub and see the live demo (works in the browser).
!pip install magika
from pathlib import Path
from magika import Magika
# Create a txt file
text_file_path = "test_file.txt"
with open(text_file_path, "w") as f:
f.write("Machine Learning Monthly is epic!")
# Classify the filetype with machine learning
m = Magika()
res = m.identify_path(Path(text_file_path))
print(res.output.ct_label)
>>> txt4) [Paper] Self-supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
Distillation is the process of taking the predictive power of a larger model and using it to improve a smaller model.
For example, take the predictive probabilities outputs of a larger model on a given image dataset and get a smaller model to try and replicate those predictive probabilities.
This process can help to get a good balance between model performance and size.
The paper above is a few years old (2021) but showcases how to improve the results of a smaller network using distillation and a relatively small dataset of 4M unlabelled images.
It shows how MobileNetV3-large can improve from 75.2% to 79% on ImageNet and ResNet50-D from 79.1% to 83%.
The same process is used to train Next-ViT models which offer excellent performance to latency ratios on smaller devices and are often fine-tuned as base models in Kaggle competitions.
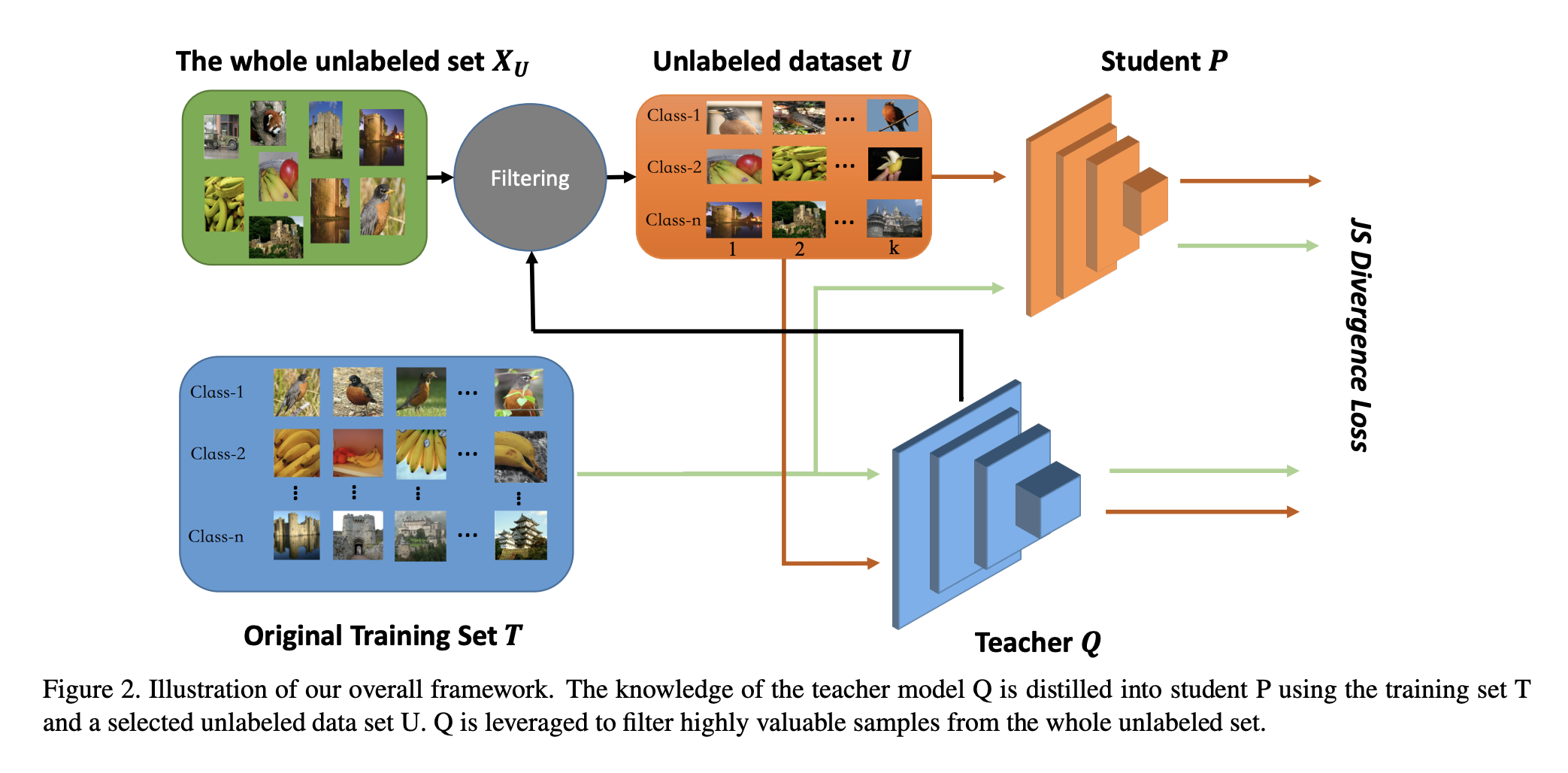
Framework for distilling the predictions of a larger teacher model into a smaller student model. The student is trained to mimic the predictive probability outputs of a teacher model. Source: https://arxiv.org/abs/2103.05959
5) Three sensational LLM-focused blog posts by Hamel Husain
Hamel is a seasoned ML Engineer and he has some of the best production-focused LLM materials on the internet. Three blog posts I’ve been reading:
- Your AI Product Needs Evals — The typical way to evaluate an LLM model is by vibe, as in, how did the output look? But this doesn't scale. What if your custom LLM could potentially output customer data (since you fine-tuned it on your own custom dataset)? The way to try and mitigate this as well as monitor performance is to create a series of evaluations/tests. In this blog post, Hamel walks you through several examples of how he's done it.
- Fuck you, show me the prompt — This blog post goes through the different LLM prompt guiding frameworks and discusses the pros and cons of each. All with the main conclusion that if you’re going to let a library write or alter your prompts for you, you better be able to get the final prompts it sends to the model back (so you can inspect them and use them later).
- Is fine-tuning (LLMs) still worth it? — Some words of experience when it comes to fine-tuning an LLM versus using a RAG-like system. Two quotes I really liked:
- “It’s impossible to fine-tune effectively without an eval system which can lead to writing off fine-tuning."
- “Generally speaking, fine-tuning works best to learn syntax, style and rules whereas techniques like RAG work best to supply the model with context or up-to-date facts.”
6) Two guides for building your own GPU server for deep learning at home
- How to build a GPU rig for personal use by felix_red_panda — A quick guide to the many different components that go into creating a deep learning PC at home. Focused on the person who knows a little bit about computer parts but wants to know how they fit together from a deep learning perspective.
- Building WOPR: A 7x4090 AI Server by Nathan Odle — How do you create a very powerful deep learning machine without paying the large prices for NVIDIA enterprise cards? You figure out how to put together 7 (yes, 7) NVIDIA RTX 4090 GPUs. This guide is not for the faint-hearted (as stated in the disclaimer, “This system is about as DIY as it gets”). But it does look really cool. Especially the old school monitor (maybe most of the budget went to the GPUs).

What a custom 7x4090 system looks like. Source: Nathan Odle blog.
7) Binary and Scalar Embeddings = Faster and Cheaper Retrieval
Embeddings are usually in float32.
Which means they use 4 bytes per dimension.
For example, if you have an embedding with 1024 dimensions, it’s going to take up 4096 bytes.
This is not much for a single embedding but scale it up to 250M embeddings and you’re going to need 1TB of memory.
However, this can be remedied with binary and scalar quantization.
Binary quantization turns embeddings into 0 or 1 values, dramatically reducing their storage requirements by 32x (compared to float32).
Scalar quantization bins embedding values between a certain range of int8 values and reduces storage requirements by 4x (compared to float32).
Each of these improves also improves the speed at which they can be queried with a minor loss of performance.

Summary of results of quantizing embeddings in regards to speed, storage and performance. Source: Hugging Face blog.
Bonus: See the demo of the power of quantized embeddings by searching over 41M Wikipedia embeddings in milliseconds.
Powered by the Mixed Bread AI, a powerful new and open-source collection of embedding and reranking models.
8) DeepMind Partners with Liverpool Football Club to build an AI Assistant Football Coach
TacticAI turns players into numerical representations and predicts their best positioning for corner kicks. Expert coaches found TacticAI placements to be indistinguishable from actual placements and often preferred the placements compared to their own.
Open-source and Research 🔍
- Two new open-source 3D model generator models. Both are capable of generating a 3D object from a single image. See TripoSR on GitHub and Stable Video 3D by Stability.ai.
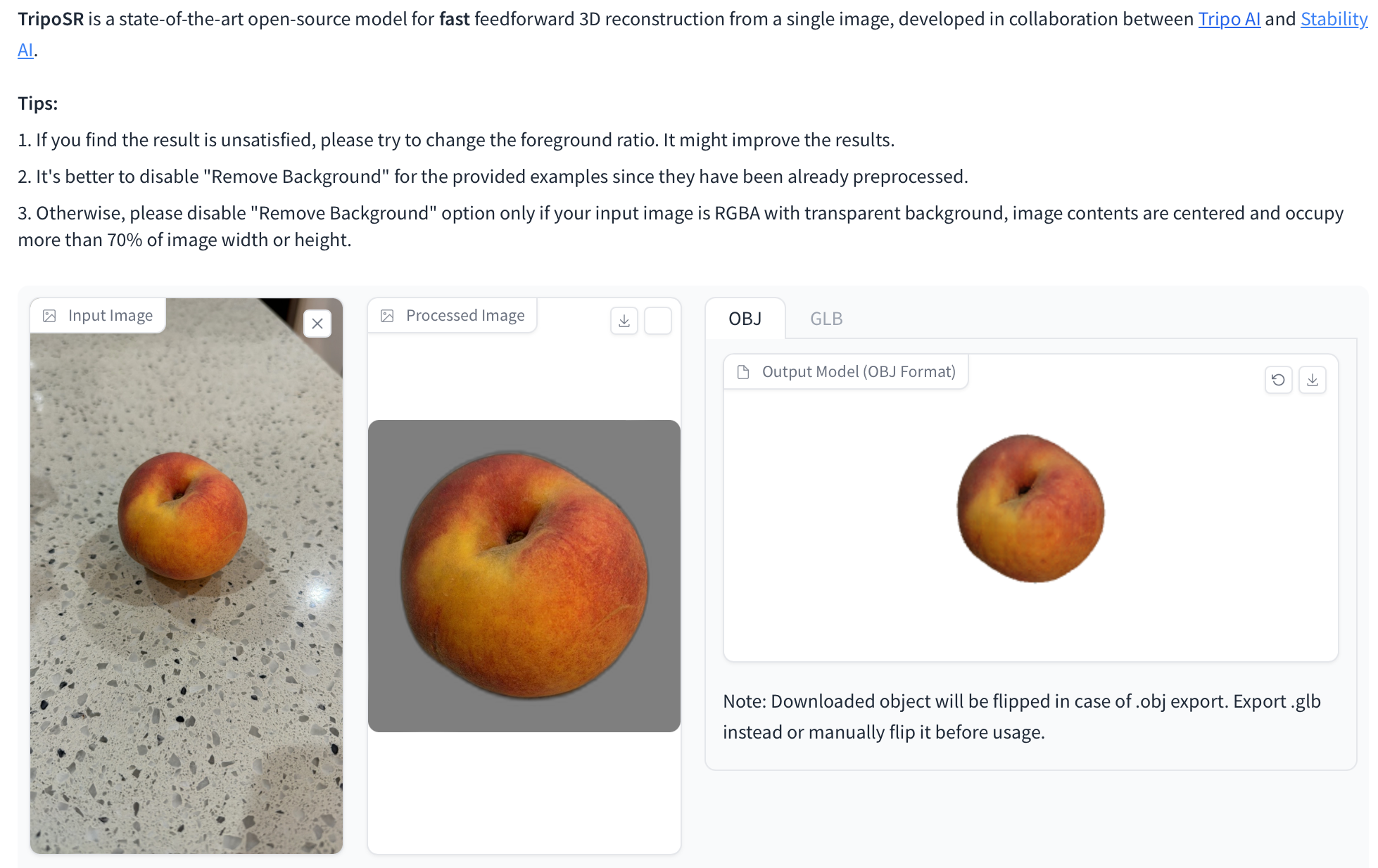
Example of creating a 3D model of a peach from a single image in seconds. Source: TripoSR on Hugging Face.
- DINOv = Segment images with visual prompting. In other words, just like Segment Anything allows you to segment an item with a dot point, DINOv offers the same except you can use multiple different kinds of prompts.
- Unsloth = a library which makes LLMs use less memory and fine-tune faster. Read their blog on how they made Gemma (an open-source LLM by Google 2.4x faster and use 58% less VRAM).
- Stable Diffusion XL Lightning is a distilled version of Stable Diffusion XL which is really fast.
- Embed, cluster and label large amounts of texts semantically with Hugging Face’s Text Clustering repo.
- Open WebUI is an open-source ChatGPT-like interface to enable you to interact with your own LLMs. GitHub, website.
- Nomic embed is the first fully and truly open-source embedding model with training data, model code, training code and model weights open-source. Fully reproducible AI ftw.
- T-RAG is a paper with lessons from the LLM trenches (what works in practice and what doesn’t for building production RAG systems).
- GLiNER is a model capable of zero-shot named entity recognition (NER) on a passage of text. Given a list of text-based entities, the model will extract the passages that relate to that entity. For example, “Apple is a technology company” + “company” → “Apple: company”.
- OmDet is an open-vocabulary object detection model capable of running in real-time. See the paper, get the model and code on GitHub.
- GaLore is a training technique which allows the pre-training of an LLM on consumer-sized GPUs (e.g. potentially pre-train a 7B model on a NVIDIA RTX 4090).
Videos, Presentations and Podcasts 🔊
- [Presentation] Thomas Wolf, Co-founder of Hugging Face and creator of Hugging Face Transformers gave a presentation on how to train LLMs in 2024. Watch presentation on YouTube, see the slides.
- [Podcast] Yann LeCun (creator of CNNs and Chief AI Scientist at Meta) went on the Lex Friedman podcast and discussed a wide range of AI topics.
- [Video Tutorial] How to use a self-hosted LLM anywhere where Ollama Web UI (now called Open Web UI) by Decoder.
- [Talk] Andrej Karpathy (former head of AI at Tesla) on making AI accessible.
- [Podcast] Roie Schwaber-Cohen, a staff developer advocate at Pinecone went on the Stack Overflow podcast and discussed how to build your own RAG system.
See you next month!
What a massive month for the ML world in March!
As always, let me know if there's anything you think should be included in a future post.
In the meantime, keep learning, keep creating, keep dancing.
See you next month,
Daniel
By the way, I'm also an instructor with Zero To Mastery Academy teaching people Machine Learning & AI in the most efficient way possible. You can see a few of our courses below or check out all Zero To Mastery courses.





















